스크랩 앱 Hoarder 사용기
여러 북마크 관리 앱과 스크랩 방법을 시도해 보다가 최근 hoarder 앱에 정착했습니다.

저는 제가 본 여러 자료들을 보관해 놓는 것을 좋아합니다. 현대에 거의 모든 문서는 온라인에 있고 이 문서들이 온라인 상에 유지될 수 있도록 뒷받침하는 서비스들이 그 역할을 계속하는 이상 주소만 알고 있으면 다시 그 문서에 접근할 수 있을 겁니다. 그런데 실제로는 그렇지 않습니다. 인터넷 상의 자료는 여러 가지 이유로 그다지 오래 유지되지 않습니다. 자료를 작성한 개인이 마음을 바꿔 자료를 삭제하기도 하고 자료를 서비스 하던 업체가 파산해 서비스가 사라지면서 서비스에 의해 제공되는 자료들이 한꺼번에 유실되기도 합니다. 이런 일을 대비해 인터넷 아카이브가 있기는 하지만 이들 역시 모든 웹사이트의 모든 버전을 백업하지는 않으며 제가 필요로 하는 문서 거의 대부분이 백업 되지 않았을 때가 더 많았습니다. 어지간한 북마크 관리 도구나 텍스트 스크랩 도구는 무료로는 주소 목록과 텍스트 스크랩을 관리해 주고 유료로는 웹사이트가 사라지더라도 기록을 남겨 주는 서비스를 제공합니다만, 일단 오직 이 목적을 위해 돈을 지불할 결정을 할 정도로 이 서비스의 역할이 절실히 필요하지 않고 또 이 서비스 역시 중단될 가능성이 있기에 온라인 상의 자료들을 먼 미래에도 찾아볼 수 있는 상태로 유지하는 것은 꽤 어려운 일입니다. 인터넷을 통해 더 많은 자료에 접근할 수 있는 세상에 살고 있지만 정작 이 자료들은 가장 최신 버전에 한하며 시간이 흐름에 따라 오래 된 자료들은 인터넷 상에서 조금씩 사라져 가 최신 버전 이외의 자료에는 접근할 방법이 완전히 사라지는 기묘한 세계에 살고 있다고 생각합니다.
지난 디지털 - 휴먼 API (2024)에서 북마크 및 읽기 목록을 관리하는데 퍼포스를 사용하고 있다고 말하면서 분명 이걸 읽는 분들은 이 행동을 기괴하다고 생각할 거라고 예상했습니다. 여러 가지 북마크 관리 서비스가 있었지만 대체로 마음에 들지 않았습니다. 그저 북마크를 관리할 거라면 저는 이미 위키를 익숙하게 사용하고 있으므로 북마크를 위키 페이지에 추가해 놓기만 하면 됩니다. 그 페이지가 유지되는 한 검색할 수도 있고 그 주소에 다시 접근할 수도 있습니다. 북마크 관리 서비스의 제 마음에 들지 않는 카테고리 관리 방법이나 태그 관리 방법에 불만을 가질 필요도 없습니다. 그냥 컨플루언스 위키 페이지에 주소를 나열해 둘 수도 있고 또 컨플루언스 데이터베이스를 만들어 기입해둘 수도 있습니다.일단 페이지를 직접 아카이빙 하지 않는 이상 사실상 모든 북마크 관리 서비스가 제 요구사항을 충족하지 못했습니다. 그래서 고민 끝에 최소한 아카이빙이라도 똑바로 할 수 있는 방법을 고안했는데 바로 페이지를 html 형식으로 저장한 다음 이를 퍼포스에 올려 놓고 관리하는 것입니다. 페이지를 아카이빙 하는 데는 SingleFile 익스텐션을 사용합니다. 이 익스텐션은 페이지 전체를 구성하는 html, 스크립트, 미디어 따위를 몽땅 html 파일 한 개로 묶어 저장해 줍니다. 미디어만 별도 디렉토리에 분리 저장하거나 어떤 소프트웨어로 읽을 수 있는지 불분명한 아카이브 파일로 만들지 않습니다. 이 익스텐션이 생성한 html 파일을 열어보면 미디어 파일을 직접 텍스트로 인코딩 해서 기록하고 있습니다 .그러니 이 파일 하나만 가지고 있으면 현대의 아무 브라우저로나 현재 보고 있는 것과 똑같은 페이지를 열어볼 수 있습니다. 대신 텍스트 형식이어서 파일 크기가 작을 거라는 예상을 완전히 깨고 그 안에 포함된 모든 미디어 파일을 인코딩 해서 저장하므로 파일 각각의 크기는 상당히 큰 편입니다. 어지간한 언론사 웹사이트에서 기사 하나를 저장하면 텍스트로는 기껏해야 몇 킬로바이트에 불과할 내용이 최소 1메가 단위의 파일로 변합니다. 하지만 서비스가 사라진 다음에도 똑같은 페이지를 사용할 수 있으니 이 정도는 아무 문제가 아닙니다.
파일 버전을 관리할 것도 아니면서 굳이 퍼포스에 등록해 두는 이유는 종종 디렉토리 단위로 파일을 분류하고 또 더 이상 필요 없게 된 파일을 삭제하면서도 미래에 삭제 기록을 모두 유지하고 싶기 때문입니다. 먼저 디렉토리는 일단 스크랩 한 페이지를 몽땅 모아 두는 디렉토리와 이 중 제가 나중에 읽어보고 나서 옮겨 놓는 아카이브 디렉토리로 나뉩니다. 일단 스크랩 한 다음 읽어보기 전까지 모든 html 파일은 같은 디렉토리에 있다가 제가 읽어본 다음 아카이브 디렉토리로 옮기거나 같은 주제끼리 모아 놓아야 할 것 같은 문서는 별도로 모아 놓습니다. 또 자료의 용도가 끝나 더 이상 유지할 필요가 없다고 판단한 파일은 삭제하는데 이 모든 이동, 삭제 과정이 퍼포스에 의해 관리되기 때문에 삭제는 제 로컬에서만 일어날 뿐 서버에서는 일어나지 않아 언제든 삭제한 문서를 되돌릴 수도 있고 또 분류가 마음에 들지 않으면 분류 이전 상태로 돌아갈 수도 있으며 현재 상태를 모두 커밋하고 나면 파일을 유실할 걱정 없이 아무 시점의 상태로 돌아갈 수도 있습니다. 이 시나리오에서 삭제는 필요 없는 파일을 제거해 스토리지 공간을 확보하는 행위라기 보다는 필요 없는 파일을 로컬 스토리지에서 제거해 더 이상 제 눈에 띄지 않는 상태로 숨기는 행동에 더 가깝습니다. 이 모든 행동은 형상관리도구인 퍼포스에 의해 기록되고 모든 행동을 기록하고 또 모든 행동을 되돌릴 수 있습니다. 이 상태가 워낙 안전하기에 온갖 시도를 편안하게 할 수 있음은 물론입니다.
하지만 이 방법을 다른 사람들에게 권유하기는 어렵습니다. 일단 개인이 형상관리도구에 기반해 파일을 관리하고 있다는 것 자체를 권유하기 어려운데 그 형상관리도구가 퍼포스이고 또 고작 파일을 스크랩 해 한 디렉토리에 모아 놓는 행동에 이를 사용할 필요는 더더욱 없기 때문입니다. 제 스스로도 이 행동에 오버헤드가 크다는 사실을 알고 있습니다. 일단 웹페이지를 스크랩 한 html 파일들은 검색이 쉽지 않습니다. 현대에는 윈도우 내장 검색도 상당히 개선된 것이 사실이고 html 파일은 근본적으로 텍스트 형식이어서 윈도우 검색에 의해 텍스트를 검색할 수 있습니다. 하지만 여전히 처음부터 검색을 고려한 스크랩 서비스들에 비해 한없이 열악한 검색 결과와 속도를 보여줍니다. 이런 시나리오에 적용할 수 있는 텍스트 파일을 직접 읽어 자체 인덱스를 구축하는 검색 솔루션을 시도해보기도 했는데 직접 파일을 인덱싱 해 검색에 응답하는 덕분에 윈도우 검색 기능에 비해 압도적으로 훌륭하게 동작했지만 제 로컬에서 이 모든 검색 기능이 동작한 덕분에 검색이잘 되기는 하지만 그 댓가로 제 컴퓨터는 항상 높은 CPU 사용률, 높은 스토리지 IO 상태를 유지하고 있었고 이 컴퓨터로 다른 작업도 해야 하는 입장에서 별로 달가운 동작이 아니었습니다. 거대한 텍스트에 대한 텍스트 기반 인덱싱이 결코 가벼운 작업이 아니라는 사실을 이해하지 못하는 것은 아니지만 고작 스크랩 한 파일을 검색하는데 이렇게 무거운 작업을 동반하고 싶지 않았습니다. 그래서 검색은 포기하고 그저 파일을 쌓는데 SingleFile 익스텐션과 퍼포스를 사용하고 있었습니다. 여러 가지 문제가 있는 상태였습니다.
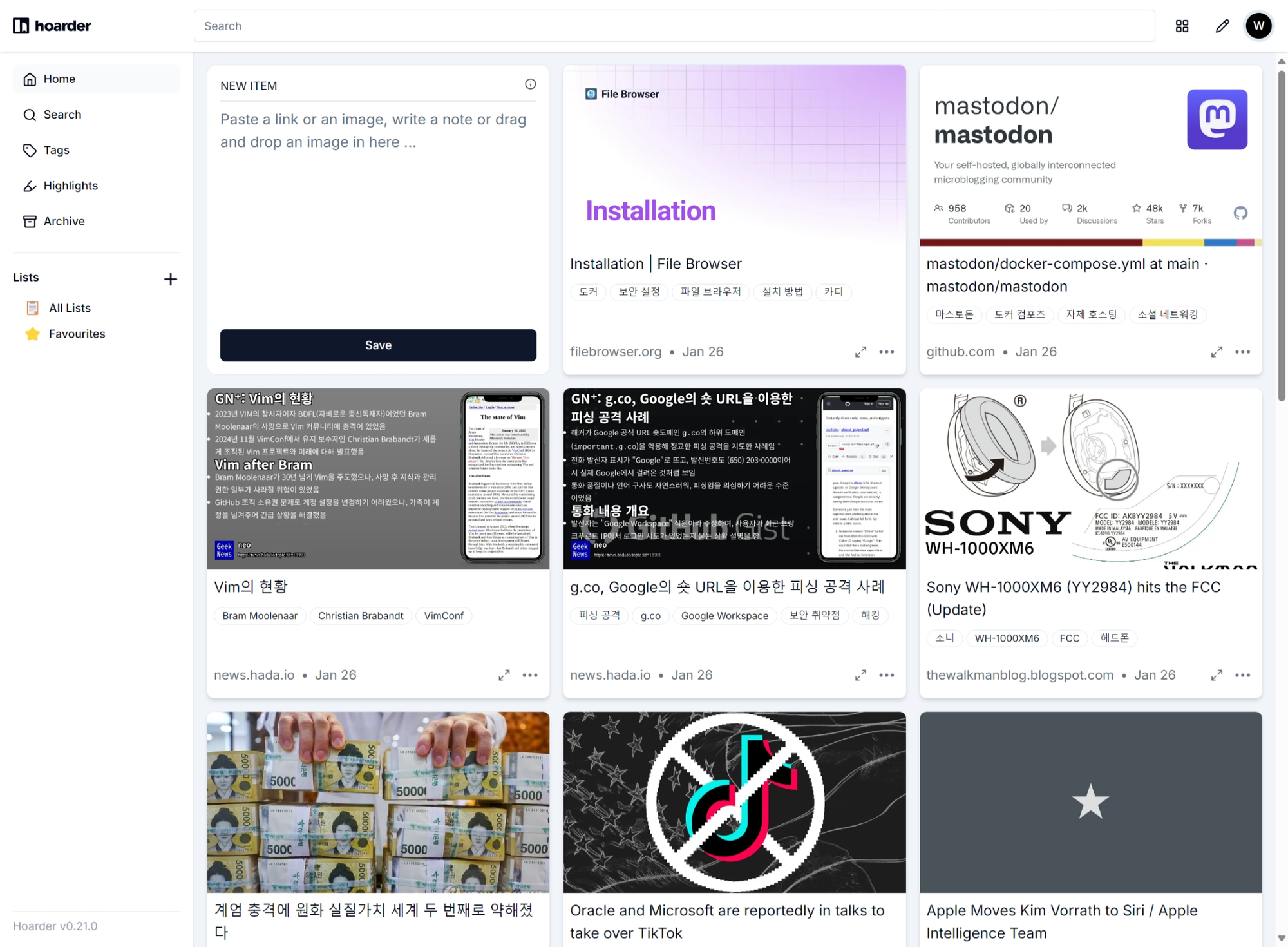
그러던 어느 날 회사의 다른 팀에 계신 분으로부터 hoarder라는 앱을 소개 받았습니다. 일단 이름부터 호더라니 인터넷 상의 여러 자료를 영속적으로 보관하고 싶어하는 사람의 요구사항을 표현하는 꽤 적절한 이름입니다. 호더 앱은 웹사이트, 브라우저 익스텐션, 스마트폰 앱 모양으로 동작하며 공개된 웹 주소를 주면 이 주소를 기록할 뿐 아니라 주소에 직접 접근해 페이지를 읽어 페이지의 텍스트, 웹페이지 전체, 그리고 만약 영상이 있다면 영상도 함께 저장합니다. 웹 주소 뿐 아니라 pdf 같은 문서 파일, 이미지 파일, 영상 파일을 던져 넣으면 이들을 나중에 다시 찾아볼 수 있는 모양으로 저장해 주는 서비스입니다. 비슷한 역할을 시도한 서비스들이 여럿 있었습니다만, 다들 텍스트와 이미지를 가져와 자신만의 형식으로 저장하려다가 페이지를 잘못 파싱해 엉뚱한 부분을 가져와 저장하기도 하고 여느 무료로 사용할 수 있는 북마크 관리 서비스들처럼 주소만 저장하려 하는 등 마음에 안 드는 점이 많았습니다. 하지만 ‘호더’는 일단 웹페이지든 문서든 이미지든 영상이든 일단 그 전체를 직접 기록합니다. 그 페이지가 나중에 존재하든 말든 관심 끄고 항상 전체 컨텐츠에 접근할 수 있도록 해 줍니다. 특히 이 서비스는 내부에 크롬 브라우저와 검색 솔루션을 내장하고 있습니다. html에 접근해 파싱한 다음 이 결과를 저장하는 접근과 달리 내장 크롬 브라우저를 사용해 페이지를 렌더링해 페이지 스크린샷을 저장하고 또 페이지 전체를 아카이브 모양으로 저장하기 때문에 어떤 포멧으로 저장되는지, 저장이 제대로 됐는지, 나중에 열어볼 수 있는지 따위에 완전히 신경 쓰지 않을 수 있습니다. 또 검색 솔루션을 포함하고 있어 로컬에서 인덱싱 하지 않아도 페이지를 스크랩 하고 나면 이미 검색 가능한 상태로 준비됩니다.
호더 앱의 중요한 특징은 외부 AI 서비스에 연결할 수 있다는 점입니다. 기본적으로 OpenAI API Key를 넣으면 웹페이지를 읽어올 때마다 이를 전달해 내용을 요약하고 또 자동으로 태그를 붙여 줍니다. 특히 이미지를 스크랩하면 이미지를 전송해 이미지에도 태그를 붙이고 또 이미지에 글자가 있다면 이를 검색 가능한 상태로 만들어 줍니다. 이들의 주장에 따르면 스크랩을 어지간히 많이 하지 않는 이상 매월 아주 적은 API 이용 요금을 지불하면 되는 수준이라고 합니다. 그런데 저는 최근에 온프레미스에서 도커 컨테이너를 더 적극적으로 활용할 목적으로, 또 공개된 인공지능 모델을 직접 로컬에서 구동하기 위해 기존 온프레미스 환경에사 사용하던 오래된 맥미니를 M4 Pro 맥미니로 교체한 참이었고 이 기계에서 llama3.3 모델이 꽤 쓸만한 속도로 구동 된다는 사실을 알고 있었습니다. 그러니 OpenAI에 돈을 내는 대신 로컬에서 구동하는 모델로 갈음할 수 있었습니다. 처음에는 페이지 요약, 태그 생성에 llama3.3 모델을 사용하고 이미지에 대한 태그 생성에는 llava:34b 모델을 사용했습니다. 새로운 페이지를 ‘호딩’하면 태그는 몇 초, 내용 요약은 십 몇 초 정도 걸렸고 이미지 태그 역시 십 몇 초 정도 걸렸는데 약간 느리다고 생각할 수 있는 속도이고 실제로 사용해 보면 그리 빠릿빠릿한 느낌이 들지는 않지만 저 혼자 사용하기에는 충분했습니다. 내용 요약과 태그가 조금 늦게 입력된다 하더라도 딱히 불편하지 않았습니다. 만약 이 속도가 마음에 안 들거나 사용자가 늘어난다면 좀 더 작은 모델로 바꾸면 아주 빠릿하게 동작하기도 하는데 페이지 요약과 태그 생성에 로컬에서 동작하는 llama3.2:3b 모델을 사용하면 정말 순식간에 동작합니다. 전에 어딘가에서 이제 근미래의 앱은 인공지능 기능을 사용하는 앱과 그렇지 않은 앱 사이에 큰 격차가 생길 거라는 내용을 읽었는데 이미 웹페이지를 로컬에 스크랩 하는 앱에서조차 자동 요약과 자동 태깅이 제공되고 있었습니다.
물론 이 인공지능 연동 기능은 아주 훌륭하지는 않습니다. 속도나 품질 이전에 동작의 일관성 측면에서 아쉬운 점이 많습니다. 만약 인간이 글을 읽고 태그를 붙인다면 글 하나만을 보고 태그를 붙이기도 해야겠지만 이전에 비슷한 다른 글을 보고 붙였던 태그를 참고해 일관성 있는 행동을 할 가능성이 높습니다. 그래야 태그 기능이 더 의미 있게 동작하기도 하고요. 그런데 로컬에서 돌아가는 인공지능 모델은 항상 새로 스크랩 하는 글 하나만 보고 태그를 붙이는 바람에 태그가 일관적이지 않습니다. 비슷한 내용의 페이지를 보고 어느 날에는 ‘애플’이라고 태그를 붙였지만 다른 날에는 ‘Apple’이라고 태그를 붙이는 식입니다. 이래서야 태그를 붙여 주기는 하지만 이를 신뢰하고 사용하기에는 조금 무리가 있습니다. 개발자들도 이를 알고 있는 모양이라 비슷하다고 생각하는 태그를 보여주고 인간이 판단해 이들을 머지 하는 기능을 제공하는데 어떤 기준으로 비슷하다고 생각하는 것인지 모르겠지만 특히 한국어에 대해서는 발음이 비슷할 뿐 의미가 전혀 다른 태그를 머지하라고 추천하곤 해서 썩 경험이 좋지는 않았습니다. 또한 llama3.3, llama3.2:3b 같은 모델은 커맨드라인에서 물어보면 한국어를 말하는 것처럼 보이지만 실제로 한국어로 된 페이지를 주고 요약하고 또 태그를 붙이라고 하면 전혀 엉뚱한 문자를 토해내거나 엉뚱한 단어, 엉뚱한 문자를 출력하는 등 문제가 있었습니다. 사실 인간이 대강 알아보는데 지장은 없었지만 어쨌든 한국어를 잘 못했습니다. 이 문제는 한국어를 잘 말한다고 알려진 llama-3-Korean-Bllossom-8B-Q4_K_M 모델을 사용하면서 꽤 개선했습니다. 태깅에 일관성이 부족한 점은 여전하지만 이는 근본적으로 호더 앱이 태그를 붙일 때 이전에 붙였던 태그 목록을 참고하는 방식으로 동작하기 이전에는 해결하기 어려울 거라고 예상합니다.
페이지 전체를 스크랩하고 이를 검색할 수 있도록 인덱싱하며 인공지능 모델을 연결하면 요약, 태깅, 이미지 태깅을 해 준다는 점은 훌륭합니다. 다만 이 앱의 이름인 ‘호더’로부터 예상할 수 있듯 이런 장점들을 제대로 활용하고 지속적으로 유지하려면 충분한 스토리지가 필요합니다. 이 앱을 본격적으로 사용하고 또 이전 퍼포스에 스크랩 했던 페이지들을 모두 다시 열어 호더 앱으로 이전하며 순식간에 꽤 큰 스토리지를 점유하게 됐습니다. 이전에 SingleFile 익스텐션으로 페이지 전체를 파일 하나로 저장하던 때에 비해 더 많은 스토리지를 사용합니다. 일단 검색을 위한 인덱스를 유지하는데 스토리지를 쓸 뿐 아니라 페이지 전체에 대한 아카이브 파일, 그리고 페이지로부터 추출한 텍스트가 별도 공간을 차지합니다. 편리하지만 본격적으로 사용하려면 큼직한 스토리지가 필요하고 스토리지 사용량 증가 역시 빠른 편이어서 이 점을 각오해야 합니다. 이 밖에 요요약 생성, 태그 생성에 사용하는 프롬프트를 수정할 수 있지만 제한적으로만 수정할 수 있고 또 태깅이 이전 글과 이전 태그를 참고해 일관된 모양으로 이루어지지 않는 점 역시 아쉽습니다. 하지만 이런 단점에도 불구하고 여전히 활발히 개발되고 있어 시간이 흐르며 이런 해결 방법을 예측할 수 있는 문제들은 빠른 속도로 수정되지 않을까 싶습니다. 이 앱이 서버에서 사용하는 CPU, GPU, 스토리지를 살펴보다가 왜 북마크 서비스에 돈을 내야 하는지 이해할 수 있었습니다.
이 글을 작성하는 2025년 초 현재 hoarder 앱은 호스팅을 제공하지 않습니다. 사용하려면 직접 어딘가에 설치해야 하는데 저는 docker-compose.yml 파일을 다음과 같이 설정해 사용하고 있습니다. 로컬에 ollama를 설치해 모델을 직접 로컬에서 돌리고 있다는 점, 그리고 웹을 통한 접근에 Cloudflare Tunnel을 사용하고 있다는 점 정도가 여느 실행과 다른 점일 것 같습니다.
services:
web:
image: ghcr.io/hoarder-app/hoarder:0.22.0
container_name: hoarder-web
restart: always
volumes:
- ./data:/data
ports:
- 3000
env_file:
- .env
environment:
MEILI_ADDR: http://meilisearch:7700
BROWSER_WEB_URL: http://chrome:9222
DATA_DIR: /data
OLLAMA_BASE_URL: http://host.docker.internal:11434
INFERENCE_TEXT_MODEL: llama-3-Korean-Bllossom-8B-Q4_K_M:latest
INFERENCE_IMAGE_MODEL: llava:34b
INFERENCE_LANG: korean
INFERENCE_JOB_TIMEOUT_SEC: 120
OCR_LANGS: kor
CRAWLER_NUM_WORKERS: 2
CRAWLER_FULL_PAGE_ARCHIVE: true
CRAWLER_VIDEO_DOWNLOAD: true
CRAWLER_VIDEO_DOWNLOAD_MAX_SIZE: -1
CRAWLER_VIDEO_DOWNLOAD_TIMEOUT_SEC: 3600
CRAWLER_STORE_SCREENSHOT: true
CRAWLER_FULL_PAGE_SCREENSHOT: true
DISABLE_SIGNUPS: true
security_opt:
- no-new-privileges=true
chrome:
image: gcr.io/zenika-hub/alpine-chrome:123
container_name: hoarder-chrome
restart: always
command:
- --no-sandbox
- --disable-gpu
- --disable-dev-shm-usage
- --remote-debugging-address=0.0.0.0
- --remote-debugging-port=9222
- --hide-scrollbars
security_opt:
- no-new-privileges=true
meilisearch:
image: getmeili/meilisearch:v1.11.1
container_name: hoarder-meilisearch
restart: always
env_file:
- .env
environment:
MEILI_NO_ANALYTICS: "true"
volumes:
- ./meilisearch:/meili_data
security_opt:
- no-new-privileges=true
cloudflared:
image: cloudflare/cloudflared:2025.1.0
container_name: cloudflared-hoarder
restart: always
command: tunnel run
environment:
- TUNNEL_TOKEN=${TUNNEL_TOKEN}
security_opt:
- no-new-privileges=true
networks:
hoarder:
driver: bridge
internal: true%
관리자 기능에는 이미 저장한 모든 주소를 다시 크롤링 해 오거나 인공지능 모델을 변경한 다음 새 모델에 기반해 기존 요약과 태그를 모두 수정하고 싶을 때 전체 데이터를 대상으로 이를 실행할 방법도 제공하고 있습니다. M4 맥미니는 평소에 거의 아무 소리를 내지 않지만 그동안 스크랩 한 모든 자료에 걸쳐 요약과 태깅을 새 모델에 기반해 수행하면 익숙하지 않은 바람 소리를 내며 동작합니다. 앞으로 계속해서 사용할 적당한 모델을 탐색하는 과정에서 모델을 변경할 일이 종종 일어나는데 이 때 사용할 일이 많이 일어납니다.
호더 앱은 지금까지 기웃거려 본 여러 북마크 관리 서비스로부터 느끼던 답답함을 상당히 많이 해결해 줍니다. 페이지 전체를 아카이빙 해 주소가 사라지든 말든 신경 끌 수 있고 호환되는 페이지에 한해서이기는 하지만 영상도 저장해 줍니다. 아직 이렇게 저장한 에셋들을 예쁘게, 그리고 효율적으로 보여준다고 보기에는 좀 거리가 있기는 하지만 앞으로 개선될 가능성이 높습니다. OpenAI 제품을 연결해 요약, 태깅 기능을 사용할 수도 있고 로컬에서 라마를 돌리고 있다면 이를 연결할 수도 있습니다. 로컬 라마는 적당한 모델을 찾는데 시간이 걸릴 수 있지만 개인적으로는 해볼 만한 시도라고 생각합니다. 그런 의미에서 뭐든 스크랩 하고 싶은 분들께 호더 앱을 추천합니다.



