엑셀에 MATCHS 함수가 필요할지도 모릅니다

여전히 일하는데 엑셀을 자주 사용합니다. 이전 프로젝트 까지는 주로 데이터 기반으로 게임을 조립하는 방식을 사용해 왔기 때문에 데이터 입력 방법으로 엑셀을 특히 더 많이 사용해 왔습니다. 엑셀은 2차원을 초과하는 데이터 모양을 입력하는데는 아주 고통스럽지만 데이터 모양을 이리 저리 잘 조정해 2차원을 초과하지 않는 모양으로 만들면 아주 오랜 기간에 걸쳐 다양한 상황에 사용할 수 있도록 개발된 덕분에 아주 편안한 그리드 모양의 데이터 입출력 도구로 사용할 수 있습니다. 그러다 보니 종종 어떤 분들은 엑셀을 위한 기형적 데이터 정의에서 설명한 오직 엑셀을 사용하기 위해 이상한 상황을 만드는 개발을 정상적으로 인지하기도 하고 지옥같이 복잡한 수식에 빠져 허우적거리며 시간을 낭비하기도 합니다.
다른 분들이 엑셀로 뭔가 만드실 때는 주로 엑셀 수식 복잡도 통제에 주의해 달라고 주문하곤 합니다. 엑셀을 다루는 우리들은 전문 프로그래머가 아니고 엑셀의 수식 입력 환경은 전문 프로그래머들이 최대한 피하기 위해 노력하는 코드 중첩을 유도하도록 만들어져 있으며 여러 조건을 중첩한 상태에서 수식 코드를 관리하기에도 불편한 환경인 데다가 너무나 초보적인 수준의 디버깅 환경 밖에 제공하지 않기 때문에 긴 수식을 똑바로 만들고 유지 보수 하기는 거의 불가능하기 때문입니다. 그래서 수식이 여러 겹으로 길어질 것 같으면 그 수식의 중간 계산 부분을 분리해 다른 칼럼이나 다른 워크시트로 분산해 여러 칼럼에 걸친 중간 계산을 추적할 수 있게 만들고 최종 결과를 가져올 때도 짧은 수식으로만 마무리할 수 있게 해 나중에 수식을 만든 자기 자신을 포함한 사람들이 워크시트의 동작을 파악하기 쉽게 만들어 달라고 주문합니다.
또 최대한 단순한 함수를 사용해 워크시트를 작성하도록 가이드 합니다. 여기서 단순한 수식과 단순하지 않은 수식을 구분하는 최대한 복잡한 함수는 VLOOKUP 입니다. 이 함수는 테이블에서 값을 조회하는데 흔히 사용하고 워크시트를 만들 때 이런 동작을 수도 없이 필요로 하지만 작은 제약이 있습니다. 가령 이 함수는 값을 검색한 다음 테이블에서 같은 행의 다른 값을 가져오려고 할 때 반드시 검색한 값보다 오른쪽에 있는 값만을 가져올 수 있습니다. 이는 워크시트를 만드는 상황에서 꽤 갑갑한 제한이어서 이 제한을 회피하기 위해 다른 방법을 생각해 보게 만듭니다.
만약 여러 데이터가 나열된 테이블 전체를 대상으로 검색할 때 검색할 가상의 값 timestamp가 테이블 맨 왼쪽에 있지 않고 테이블 중간에 있다고 가정해 봅시다. 이 상황에서 VLOOKUP을 사용해 원하는 데이터를 포함한 행 번호를 찾을 수 있지만 실제 가져올 값은 반드시 timestamp 오른쪽에 있어야만 합니다. 만약 timestamp의 왼쪽에 위치한 값을 가져오려면 VLOOKUP 대신 INDEX, MATCH 함수 조합을 사용해야 하고요. 사실 이 역시 VLOOKUP에 비해 복잡하다고 말하기는 어렵지만 꽤 많은 사람들이 이 두 함수의 조합을 안전하게 사용하기 어려워 하고 종종 인자 입력에 실수해 수식을 깨거나 더 나쁘게는 잘못된 행 번호와 값을 반환하게 만들어 문제를 일으키기도 합니다. 이런 상황을 해결하기 위해 아예 INDEX, MATCH조합을 사용할 상황을 만나면 차라리 timestamp 칼럼을 실제 가져올 값보다 왼쪽으로 보내 VLOOKUP을 사용해도 되는 상황으로 만든 다음 더 이해하기 쉽고 실수하지 않을 수 있는 모양으로 바꾼 다음 워크시트를 만들라고 조언합니다.
하지만 분명 앞에서 저 자신을 포함한 우리들은 전문 프로그래머가 아니고 엑셀 수식은 프로그래머들이 피하려고 하는 괄호 중첩 모양으로 수식을 작성하도록 유도하는 구조일 뿐 아니라 수식 입력 인터페이스가 복잡한 수식을 다루기에 적합하지 않고 또 한 줄 짜리 수식을 디버깅 하는데 충분하지 않은 기능만을 제공하기 때문에 길고 복잡한 수식을 함부로 작성해서는 안된다고 이야기 했습니다. 하지만 제 스스로는 가끔 이런 상황을 마주치면 다른 워크시트나 칼럼을 만들어 계산 중간 과정을 분리하는 대신 어지간하면 수식 한 줄로 처리를 끝내 수식 하나만 붙여 넣으면 바로 계산할 수 있는 모양을 만들고 싶어집니다. 사실은 이건 시간을 낭비하는 행동이지만 종종 한 줄로 해결할 수 있는데 굳이 워크시트를 만들고 다른 칼럼을 만들어 중간 계산 과정을 분리해야 할지 고민하고 또 그건 너무 귀찮은 일이 아닐지 생각하곤 합니다.
지난 홀더 테스트 후 몇몇 로그를 수집하고 분석해야 했는데 로그를 쌓기는 했지만 이를 분석하는 일은 또 다른 문제입니다. 원래는 이런 역할을 전문적으로 하는 데이터과학자라는 직업이 있지만 우리들 같은 듣보가 그런 전문성 있는 분을 모시기는 불가능할 겁니다. 결국 이런 애매한 작업은 기획팀에 도착하고 어쩌다 보니 과거에 쿼리를 작성해 본 적 있는 사람에게 일이 도착해 어쩔 수 없이 오픈서치에 적재된 로그를 요구사항에 맞게 가공해 결과를 보고하는 일을 하게 됩니다. 그런데 오픈서치의 쿼리 워크벤치는 베이직 쿼리만 제공할 뿐 아니라 흔히 사용하는 COUNT, DISTINCT 같은 집계 명령들이 결과를 200개만 돌려주는 제약이 있었습니다. 처음엔 이 제약 안에서 어떻게든 할 수 있을 줄 알았는데 시행착오를 겪다 보니 쿼리 하나 안에 집계 명령이 여러 개 들어가면 각자가 결과를 200개 까지만 반환해 이상한 최종 결과를 되돌려 줍니다.
이 문제로 몇 시간을 허공에 버린 다음에서야 쿼리 워크벤치로는 집계 명령 없이 조건에 맞는 데이터를 조회하는데만 사용하고 여기서 얻은 데이터는 엑셀에서 집계하기로 결정합니다. 아마 다음에는 오픈서치에서 이런 제약을 완화하거나 제거할 방법을 찾거나 로그를 더 편안히 조회할 수 있는 다른 환경으로 가져와 가공할 방법을 찾아야 할 것 같지만 이번에는 당장 엑셀 말고는 다른 방법을 떠올리지 못했습니다. 그런데 이런 로그 조회에서 주로 하는 행동은 2차원으로 드넓게 펼쳐진 여러 행의 데이터에서 하나 이상의 조건에 맞는 행을 찾은 다음 그 행으로부터 다양한 데이터를 가져와 이들을 더하거나 중앙값을 구하거나 분포를 파악하거나 수를 세는 일이 대부분입니다.
그런데 위에서 이야기했지만 우리들이 엑셀을 다룰 때 최대 복잡성의 기준으로 삼은 VLOOKUP은 한 번에 한 조건을 검색할 수밖에 없었고 그나마 검색한 값 오른쪽에 있는 데이터만을 가져올 수 있어 이번 처럼 한 행에 있는 여러 값에 걸쳐 검색하고 그 결과 역시 행의 아무 데서나 가져올 수 있어야 하는 요구사항에 맞지 않습니다.
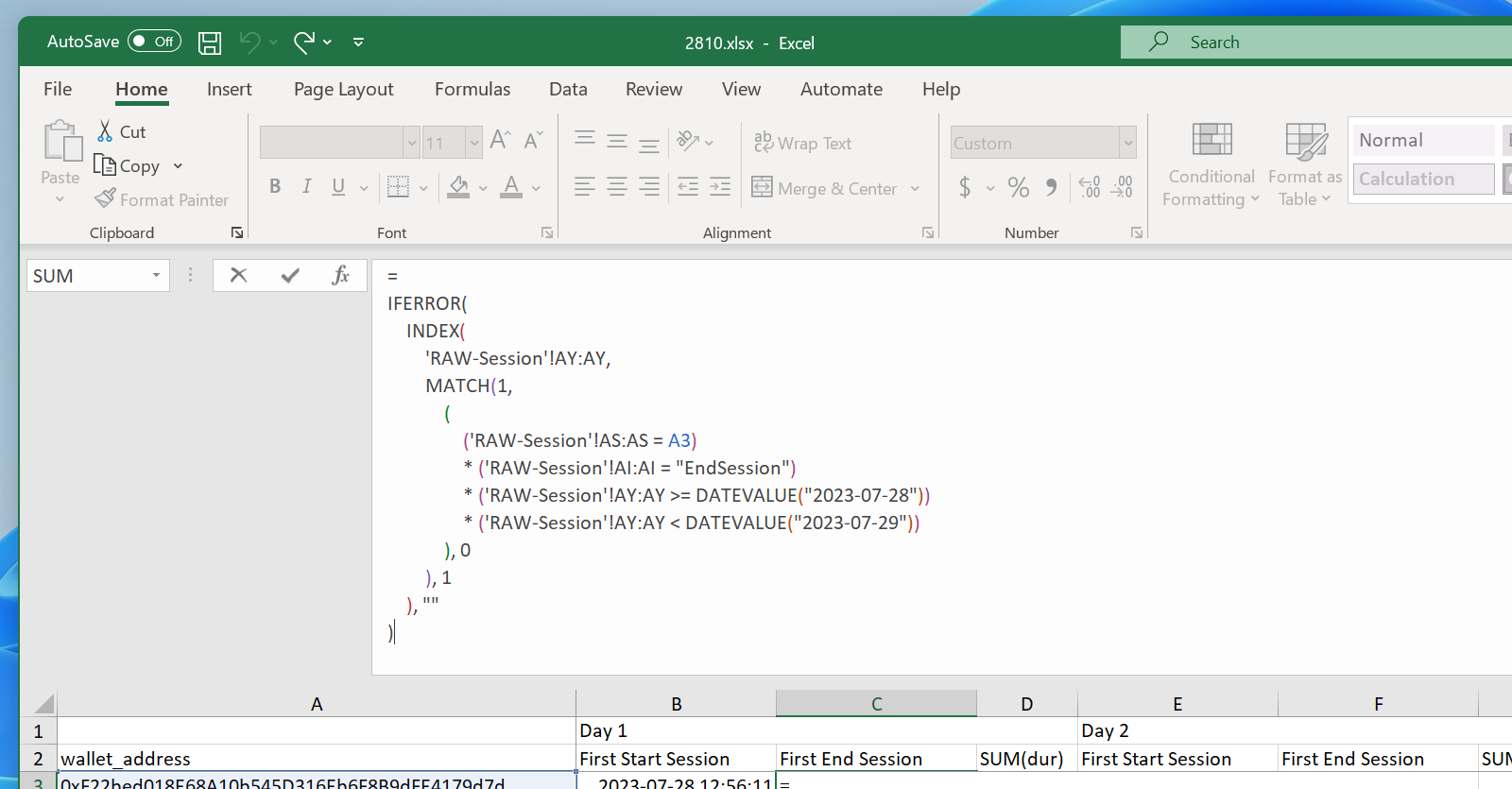
팀원 분들께 그동안 해 온 엑셀 수식 복잡도 통제를 따라야 하는 상황임에 틀림 없었지만 갑자기 괜히 검색할 상황에 맞춰 데이터를 가공하고 중간 계산 과정을 분리하기가 귀찮아져 항상 스스로 말하던 원칙을 깨고 그냥 한 줄 짜리 수식을 만들기 시작합니다. 요구사항 자체는 단순했습니다. 오픈서치에 적재된 로그는 여러 단계로 중첩된 JSON 모양이었지만 쿼리 워크벤치로 조회할 때는 이 모든 값이 2차원으로 펼쳐진 커다란 테이블 모양으로 조회되고 또 조회 자체도 중첩을 무시하고 모든 데이터가 펼쳐져 있다고 생각하고 조회하면 됐습니다.
그래서 조회 결과 역시 모든 값이 여러 행과 열에 걸쳐 펼쳐진 모양으로 나타나는데 여기서 원하는 조건 여러 가지에 일치하는 행을 뽑으려면 여러 조건을 동시에 만족하는 행을 찾아야 하고 그러려면 웬만하면 사용을 피하라고 말해 온 INDEX와 MATCH의 조합을 사용해야 하는 상황입니다. 또한 조건 여러 개를 만족하는 행을 찾기 위해 애초에 입력을 배열로 받는 MATCH의 동작 특성을 응용해 조건 하나를 괄호 하나 안에 넣고 배열에 대한 조건 연산 결과가 TRUE 또는 FALSE로 표현되도록 한 다음 이들을 곱한 결과를 찾도록 하는 방식으로 여러 조건을 한 번에 찾도록 만들었습니다.
결과를 들여쓰기로 눈에 잘 들어오게 만든 다음 보면 단순하지만 수식을 수식 편집기 기본 상태인 한 줄만 보이는 상태로 놓고 전체를 한 번에 타이핑하고 중간에 괄호가 짝이 맞도록 입력하고 또 수정하는 건 그리 간단하지 않았고 중간에 예상보다 시간을 더 쓰고 있음을 알게 되면서 부터 정작 다른 분들께는 이러지 말라고 해 놓고 스스로는 이러고 있는 상황이 너무나 부끄러웠습니다. 또 이런 계산은 엑셀에서 계산 속도가 느려 이런 수식을 수 만 라인에 걸쳐 붙여 넣으면 엑셀이 굳은 채로 수 십 초 동안 계산을 하기도 하는데 생각해보면 그럴 법도 한 것이 인덱스 없는 테이블에 별 것 아닌 조회 쿼리를 실행하면 결과를 내는데 한 세월 걸리는 것과 별로 다르지 않을 겁니다.
여튼 오픈서치에서 시행착오를 겪고 또 엑셀에서 시행착오를 겪은 끝에 요구사항에 맞는 로그를 집계하기는 했지만 오픈서치와 엑셀 양쪽 모두에 아쉬움이 남는 경험이었습니다. 오픈서치는 기왕 쿼리 워크벤치를 지원할 거면 좀 더 제대로 된 표준 쿼리를 지원해야 할 것 같고 또 집계 명령에 제한이 있다면 애초에 집계 쿼리를 지원해서는 안 될 것 같습니다. 될 것 같이 보이고 또 되는 것 같은데 그 결과가 이상한 결과일 경우 항상 결과를 의심하고 이를 점검하는 평소 같으면 필요 없는 과정을 항상 거쳐야 해서 일이 피곤해집니다. 엑셀 역시 결국 커다란 2차원 테이블에서 여러 칼럼에 걸친 조건을 검색하고 그 결과에 따라 한 행의 여러 값을 가져올 일이 종종 생기고 이런 요구사항이 그리 특별한 것 같지도 않습니다. 때문에 SUMIFS나 COUNTIFS처럼 조건을 검색할 때 여러 조건을 명시적으로 입력할 수 있는 가칭 MATCHS 같은 기능을 제공해야 하지 않을까 싶었습니다.



